neuromorphic Computing
AI that thinks in charge,
not clock cycles
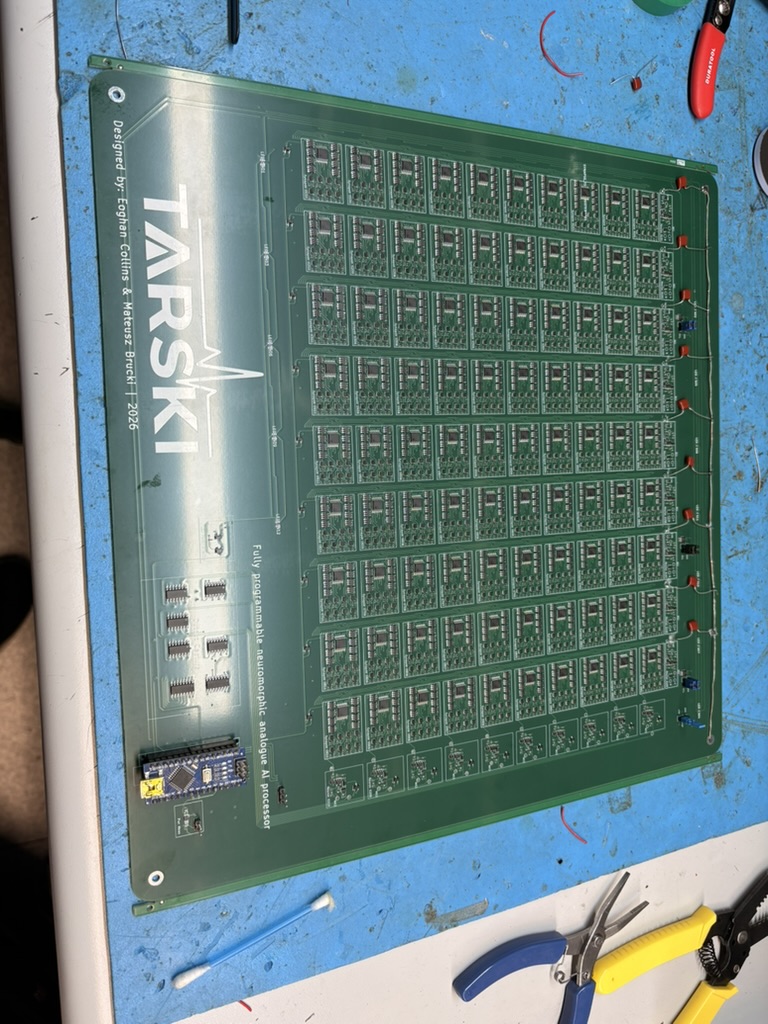
A programmable analogue spiking neural network chip, built from discrete off-the-shelf components. Its analogue core classifies digits at microjoules per inference: three orders of magnitude below the digital overhead on the same task.
7.4µJ
Analogue compute per inference
85.1%
MNIST, emulated board round-trip
6,000,000×
Faster simulation than SPICE